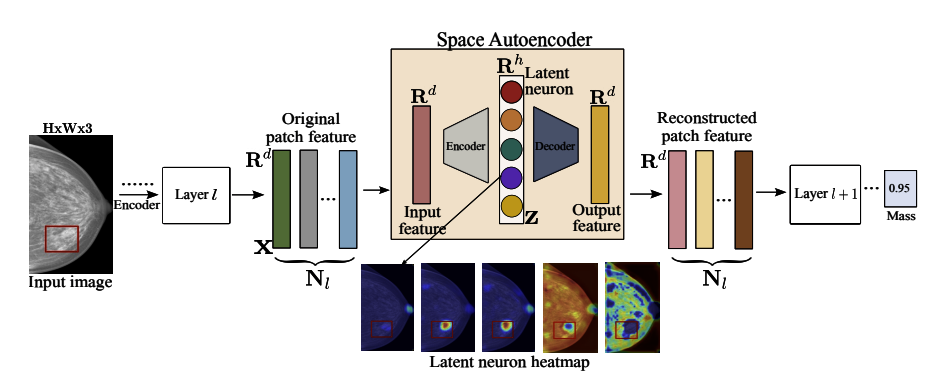
Step 1: Feature Extraction
Given an input image I, we extract local features from a pretrained Mammo-CLIP model at a specific layer l. Each spatial position j in the feature map yields a vector xlj ∈ ℝd, where d is the feature dimension and Nl = Hl × Wl is the number of spatial locations.
Step 2: Sparse Autoencoder Training
The extracted feature xlj is encoded using weight matrix Wenc ∈ ℝd×h, passed through a ReLU nonlinearity, and decoded using Wdec ∈ ℝh×d. The training objective combines reconstruction and sparsity:

This encourages the autoencoder to reconstruct input features while activating only a small number of latent neurons, enabling interpretability.
Step 3: Identifying Concept-Neurons
After training, we compute the class-wise mean latent activation z̄(c) ∈ ℝh over all examples in class c ∈ {0, 1}:

Each latent neuron t is scored by its activation st(c) = z̄t(c), and top-scoring neurons are considered concept-aligned.
Step 4: Visualization and Semantic Probing
We visualize input patches that strongly activate each latent neuron. This reveals whether the neuron focuses on meaningful clinical patterns (e.g., masses, calcifications) or irrelevant areas.
Step 5: Latent Interventions
We intervene on the latent activations z = ReLU(Wenc · xj) by either retaining or suppressing specific neurons:
-
Top-k Activated: Keep only the top-k neuron activations:

-
Top-k Deactivated: Suppress the top-k neurons:

By comparing the model's outputs before and after intervention, we assess whether the top neurons carry meaningful information or reflect confounding artifacts.